|
Prasanna Mayilvahanan I'm a fourth-year Ph.D. student at the Max Planck Institute for Intelligent Systems, Germany. Previously, I was a Research Intern at Cohere working on exploration methods and reward modeling for LLM reasoning, and at Apple MLR working on LLM pre-training and data curation. Prior to this, I completed my master's studies at USI Lugano / ETH Zurich, and my bachelor's at IIT Guwahati. Email / CV / Research Statement / Blog / Scholar / Twitter / Github |
|
ResearchMy research spans benchmarking LLM reasoning capabilities, robustness of LLMs and VLMs, and foundations of representation learning. I am particularly interested in developing methods that enable models to 'extrapolate beyond their training distribution.' Currently, I focus on (1) exploration-driven RL approaches that push models beyond their base capabilities, and (2) novel architectures, training objectives, and data curation strategies that promote creative generalization. Selected papers are highlighted. |
|
MentisOculi: Revealing the Limits of Reasoning with Mental Imagery
Jana Zeller, Thaddäus Wiedemer, Fanfei Li, Thomas Klein, Prasanna Mayilvahanan, Matthias Bethge, Felix Wichmann, Ryan Cotterell, Wieland Brendel arXiv preprint, 2026 arXiv / project page Can models reason better with intermediate visualizations, akin to human mental imagery? MentisOculi evaluates this across frontier models and finds that visual thoughts do not yet improve reasoning. |
|
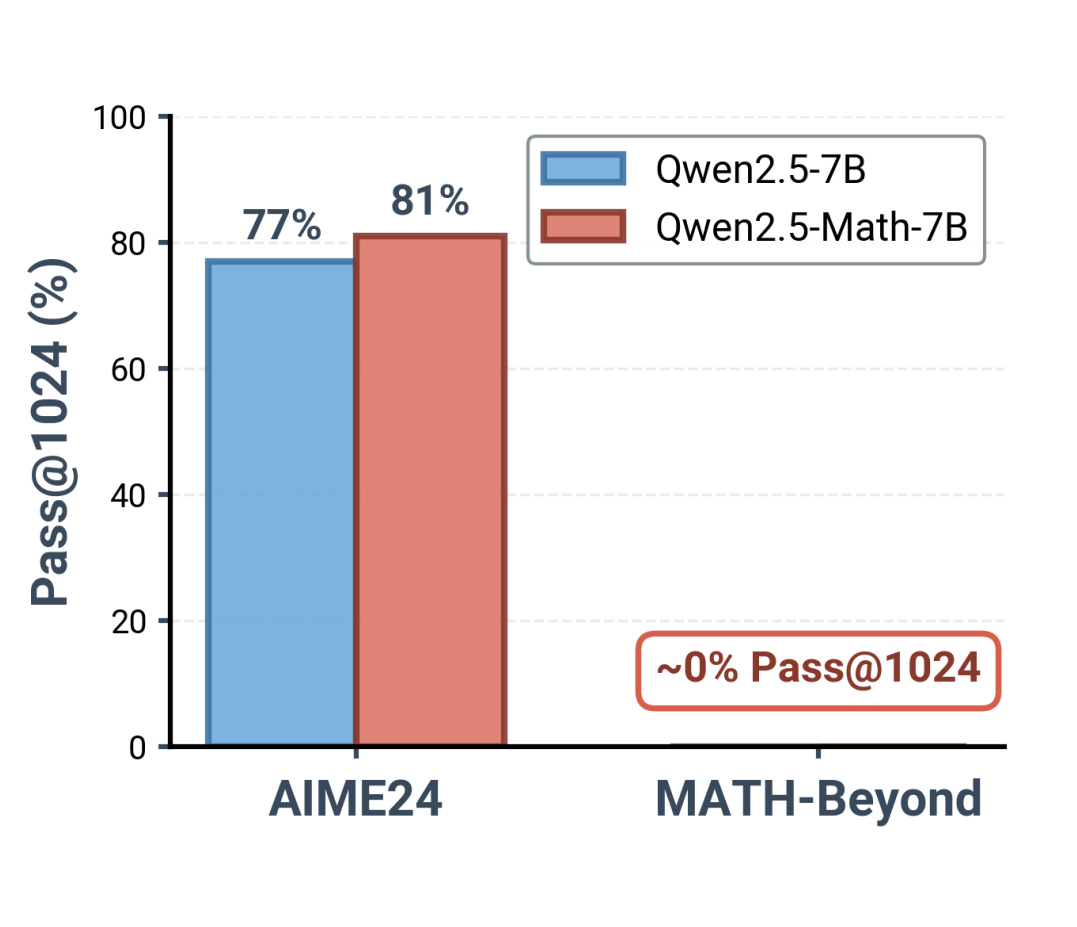
MATH-Beyond: A Benchmark for RL to Expand Beyond the Base Model
Prasanna Mayilvahanan, Ricardo Dominguez-Olmedo, Thaddäus Wiedemer, Wieland Brendel ICLR, 2026 arXiv / code / data Can RL post-training discover genuinely new solution paths, or does it merely sharpen what the base model already knows? MATH-B is a diagnostic benchmark designed to tell the two apart. |
|
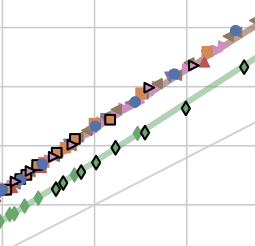
LLMs on the Line: Data Determines Loss-to-Loss Scaling Laws
Prasanna Mayilvahanan*, Thaddäus Wiedemer*, Sayak Mallick, Matthias Bethge, Wieland Brendel ICML, 2025 arXiv / project page We find that two substantially different training setups—differing in architectures, tokenizers, optimizers, etc.—when trained on the same data and achieving identical training losses, consistently yield matching downstream performance across diverse tasks. |
|
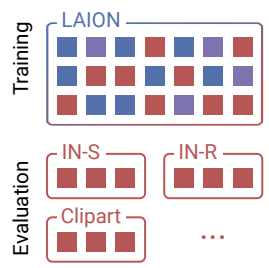
In Search of Forgotten Domain Generalization
Prasanna Mayilvahanan*, Roland S. Zimmermann*, Thaddäus Wiedemer, Evgenia Rusak, Attila Juhos, Matthias Bethge, Wieland Brendel ICLR, 2025 (Spotlight) arXiv / project page CLIP's high performance on style-centric domain shifts is significantly influenced by the presence of such images in its training set. |
|
Does CLIP's Generalization Performance Mainly Stem from High Train-Test Similarity?
Prasanna Mayilvahanan*, Thaddäus Wiedemer*, Evgenia Rusak, Matthias Bethge, Wieland Brendel ICLR, 2024 arXiv / project page CLIP's ability to generalize to standard OOD benchmarks does not mainly stem from exact duplicates and near-duplicates in its training dataset. |
|
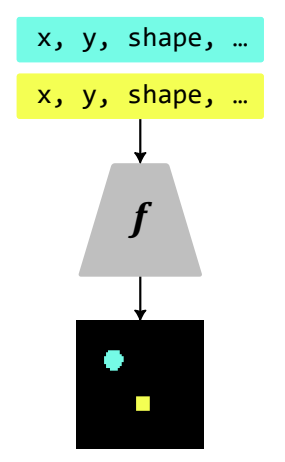
Compositional Generalization from First Principles
Thaddäus Wiedemer*, Prasanna Mayilvahanan*, Matthias Bethge, Wieland Brendel NeurIPS, 2023 arXiv We introduce a theoretical framework to analyze compositional generalization of neural networks within the regression setting. |
|
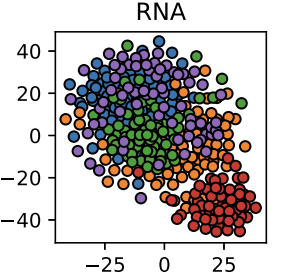
Representation Learning for the Clustering of Multi-Omics Data
Gautier Viaud, Prasanna Mayilvahanan, Paul-Henry Cournède IEEE/ACM TCBB, 2022 paper We provide a neural network-based representation learning and clustering method for multi-omics data integration. |
|
* denotes equal contribution |